Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
At present, the navigation mode based on visual/Inertia has been successfully applied in the actual planetary rover mission, and played an important role in the patrol process. On the one hand, it obtains a large amount of surface environmental data, on the other hand, it ensures the effective detection and identification of obstacles on the patrol path. But it still reveals some problems: First, based on the existing sensing load, the material and mechanical characteristics of the terrain environment cannot be effectively perceived, so that the patrol does not have the ability to recognize the classification of terrain with different materials. Second, existing sensing loads are susceptible to environmental changes, which make the patrol not capable of carrying out complex tasks for a long time abroad. Therefore, this project proposes a new idea of the external environment perception based on the visual/vibration fusion. It is intended to use the fusion of the two sensing modes to achieve terrain reconstruction, classification perception and semantic mapping of the detection environment, thereby overcoming the harm caused by the above problems.
Unmanned and intelligent technologies are the future development trend in the business field; particularly, during major epidemics or disasters, how to provide business services safely and securely is crucial. Specifically, providing users with resilient and guaranteed communication services is a challenging business task when the communication facilities are damaged. Unmanned aerial vehicles (UAVs), with flexible deployment and high maneuverability, can be used to serve as aerial base stations (BSs) to establish emergency networks. However, it is challenging to control multiple UAVs to provide efficient and fair communication quality of service (QoS) to users. In this project, we propose a learning-based resilience guarantee framework for multi-UAV collaborative QoS management. We formulate this problem as a partial observable Markov decision process and solve it with proximal policy optimization (PPO), which is a policy-based deep reinforcement learning method. A centralized training and decentralized execution paradigm is used, where the experience collected by all UAVs is used to train the shared control policy, and each UAV takes actions based on the partial environment information it observes. In addition, the design of the reward function considers the average and variance of the communication QoS of all users. Extensive simulations are conducted for performance evaluation. The simulation results indicate that 1) the trained policies can adapt to different scenarios and provide resilient and guaranteed communication QoS to users, 2) increasing the number of UAVs can compensate for the lack of service capabilities of UAVs, 3) when UAVs have local communication service capabilities, the policies trained with PPO have better performance compared with the policies trained with other algorithms. 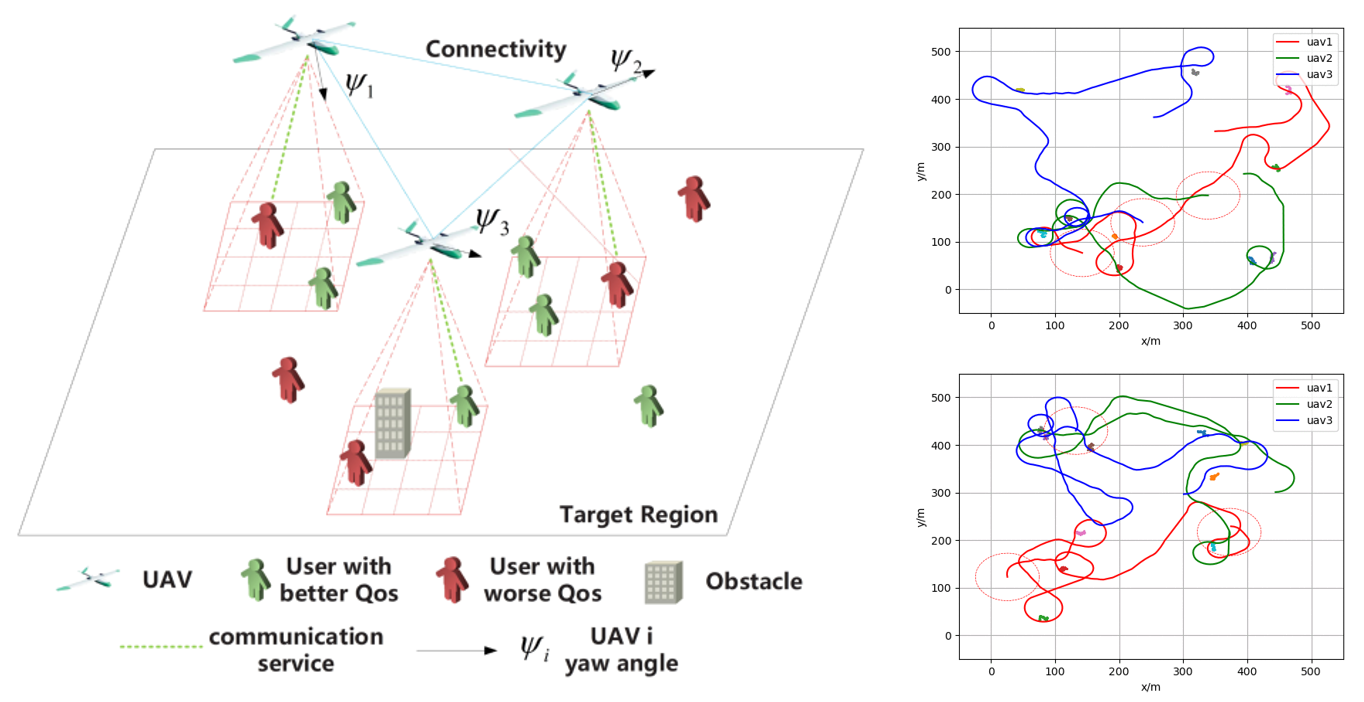
Multi-robot formation control has been intensively studied in recent years. In practical applications, the multi-robot system’s ability to independently change the formation to avoid collision among the robots or with obstacles is critical. In this project, a multi-robot adaptive formation control framework based on deep reinforcement learning is proposed. The framework consists of two layers, namely the execution layer and the decision-making layer. The execution layer enables the robot to approach its target position and avoid collision with other robots and obstacles through a deep network trained by a reinforcement learning method. The decision-making layer organizes all robots into a formation through a new leader–follower configuration and provides target positions to the leader and followers. The leader’s target position is kept unchanged, while the follower’s target position is changed according to the situation it encounters. In addition, to operate more effectively in environments with different levels of complexity, a hybrid switching control strategy is proposed. The simulation results demonstrate that our proposed formation control framework enables the robots to adjust formation independently to pass through obstacle areas and can be generalized to different scenarios with unknown obstacles and varying number of robots. 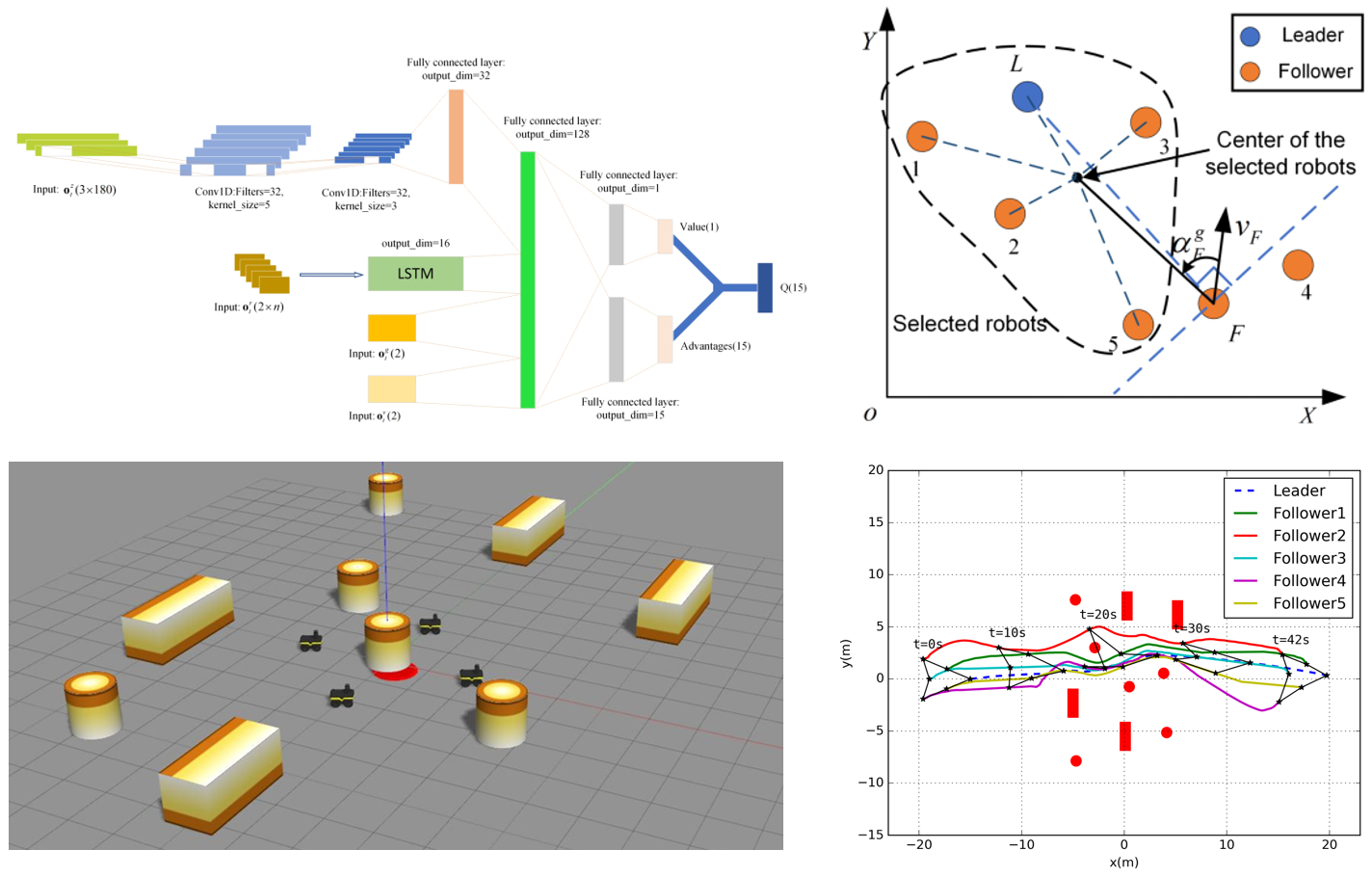
In order to satisfy the need for large-scale, decentralized and multi-agent collaborative work in the future, and to realize safe operation in the process of fully autonomous/human-computer interaction, multi-robot reinforcement learning has gradually become a research hotspot in the field of machine learning (ML). There has been an intensive and in-depth research on decentralized and centralized learning, but it is still mainly based on collaborative learning between multiple robots. In this project, we present a clever extension to the single-agent robot, and propose a decentralized multi-agent reinforcement learning method (D-MARL) for a multi-part single robot body by constructing a graph network. In addition, the ability of safe and robust autonomous collaborative learning is the key to the degree of intelligence of multi-robots and to decide whether they can get out of the laboratory and move towards real-life applications. The question of how to effectively explain the nature of the learning process is the bottleneck of the current ML. To this end, this article starts from the perspective of resilience guarantee and gives the design of the critic function based on the Lyapunov stability theory. Finally, we compared and verified the proposed method in a Multi-Agent Mujoco environment, and its resilience ability was evaluated under multi-scale constant impulse disturbance and mass loss disturbance. The results can prove that the D-MARL method proposed in this project presents a significant improvement in the learning rate and anti-interference transfer ability compared with the multi-agent soft actor-critic (MASAC) and multi-agent deep deterministic policy gradient (MADDPG).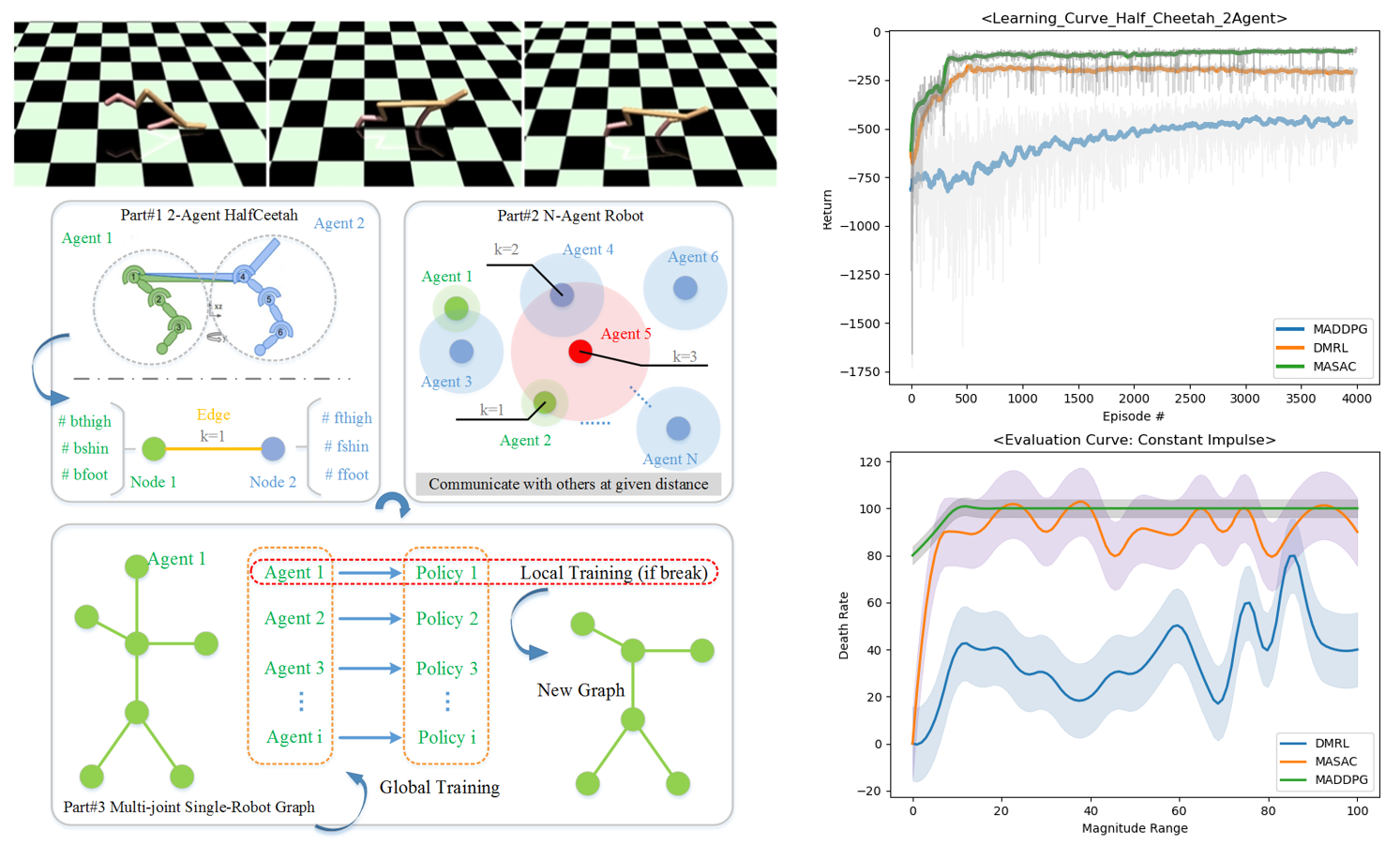
In recent years, the motion planning algorithm based on reinforcement learning has shown its potential to meet the requirements of high-dimensional planning space, complex task environments, and fast online planning simultaneously. However, the performance of the reinforcement learning-based motion planning algorithm for manipulators is closely related to the quality of the reward function, which is typically designed manually. In this project, inspired by heuristic functions, a new learning-based reward function design framework is proposed. By relaxing the constraint of the original motion planning problem, a simple task is established. The cost of a solution to the simple task is taken as a heuristic for the original problem, and the heuristic is then incorporated into the reward function. We tested the performance of heuristic-guided reward functions based on the soft-actor-critic algorithm in various difficult scenarios. The experimental results showed that our reward function design method improves the convergence speed of the reinforcement learning training process and the planning success rate of the policy obtained after the training. In addition, the trained motion planning policy could be directly transferred to a real manipulator for online execution without modification, thus verifying the flexibility of the strategy between simulated and real environments.
In this project, a minimum-fuel powered-descent optimal guidance algorithm that incorporates obstacle avoidance is presented. The approach is based on convex optimization that includes the obstacles using nonconvex functions. To convert these nonconvex obstacle constraints to convex ones, a simple linearization procedure is employed. It is proved that the optimal solution of the convex relaxation problem is also optimal for the original nonconvex one. The sensitivity of the multiobstacle avoidance method to the relaxation factor and its effectiveness under different conditions are also investigated through simulations.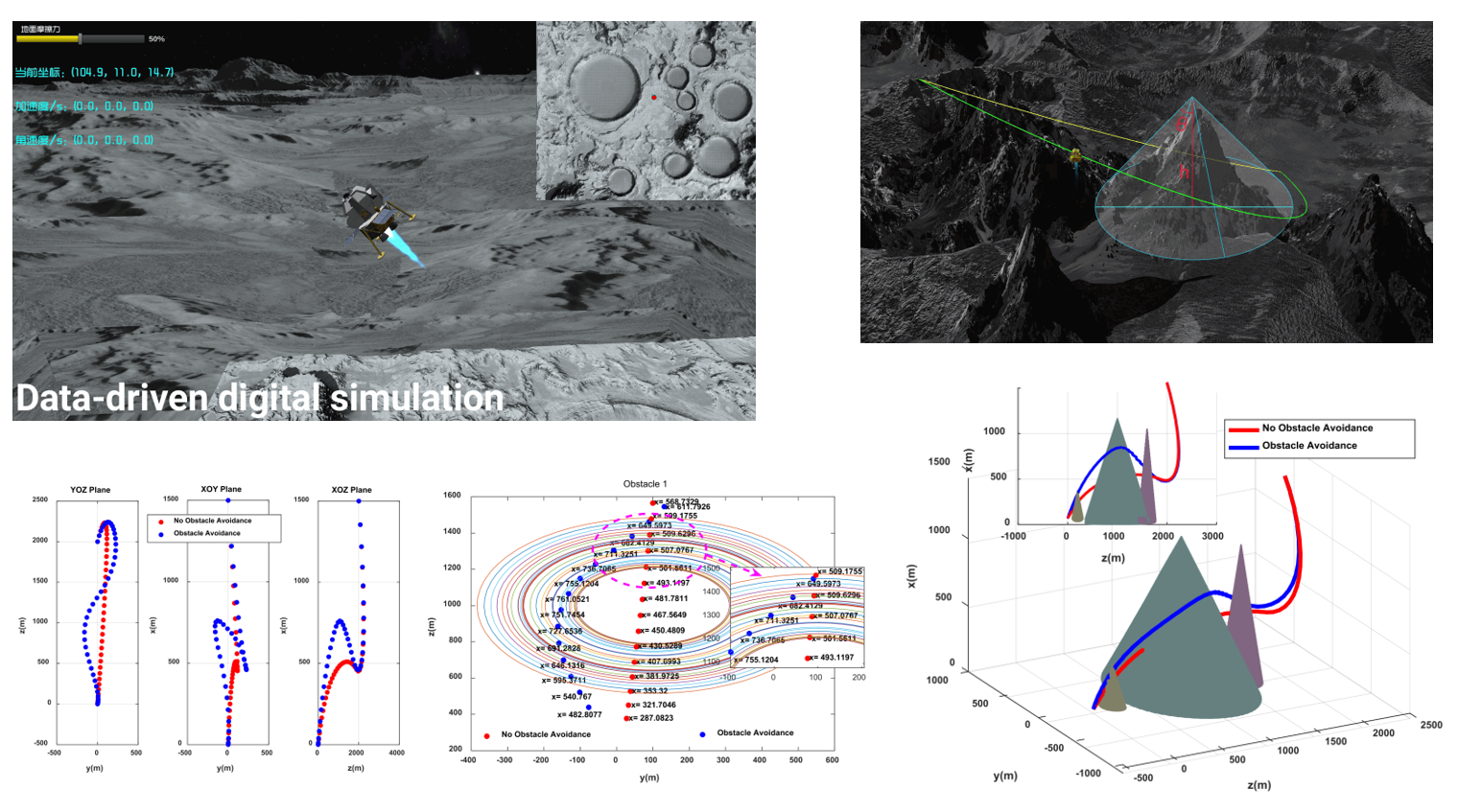
Published in IEEE Access, 2019
Chengchao Bai, Jifeng Guo, Hongxing Zheng.
Recommended citation: Chengchao Bai, Jifeng Guo, Hongxing Zheng. (2019). "Three-Dimensional Vibration-Based Terrain Classification for Mobile Robots." IEEE Access. Volume 7. https://ieeexplore.ieee.org/document/8713978
Published in IEEE Transactions on Aerospace and Electronic Systems, 2019
Chengchao Bai, Jifeng Guo, Hongxing Zheng.
Recommended citation: Chengchao Bai, Jifeng Guo, Hongxing Zheng. (2019). "Optimal Guidance for Planetary Landing in Hazardous Terrains." IEEE Transactions on Aerospace and Electronic Systems. Early Access. https://ieeexplore.ieee.org/document/8911470
Published in Journal of Astronautics(宇航学报), 2020
Xibao Xu, Chengchao Bai, Yusen Chen, Haonan Tang.
Recommended citation: Xibao Xu, Chengchao Bai, Yusen Chen, Haonan Tang. (2020). "A Survey of Guidance Technology for Moon/Mars Soft Landing." Journal of Astronautics. 41(06). https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2020&filename=YHXB202006010&uniplatform=NZKPT&v=M7s9Sid96j_VOZ_cgqQgDv5HlzIKMXOb2nww8-HcXoTAyu5f8kDsuPWYrfzAdi9A
Published in Pattern Recognition, 2021
Chengchao Bai, Peng Yan, Xiaoqiang Yu, Jifeng Guo.
Recommended citation: Chengchao Bai, Peng Yan, Xiaoqiang Yu, Jifeng Guo. (2021). "Learning-based resilience guarantee for multi-UAV collaborative QoS management." Pattern Recognition. 122(108166). https://www.sciencedirect.com/science/article/pii/S0031320321003538
Published in IEEE Transactions on Intelligent Transportation Systems, 2021
Chengchao Bai, Peng Yan, Wei Pan, Jifeng Guo.
Recommended citation: Chengchao Bai, Peng Yan, Wei Pan, Jifeng Guo. (2022). "Learning-based Multi-Robot Formation Control with Obstacle Avoidance." IEEE Transactions on Intelligent Transportation Systems. Early Access. https://ieeexplore.ieee.org/document/9527169
Published:
Published:
Published:
Student Associations course, Harbin Institute of Technology, IARIA, 2018
Master Student course, Harbin Institute of Technology, 2019
Master Student online course, Delft University of Technology, Harbin Institute of Technology, 2020